
|
eValid™ -- Automated Web Quality Solution
Browser-Based, Client-Side, Functional Testing & Validation,
Load & Performance Tuning, Page Timing, Website Analysis,
and Rich Internet Application Monitoring.
© Copyright 2000-2011 by Software Research, Inc.
|
|
eValid -- InBrowser™ Advantages for Site Analysis
[eValid vs. HTTP/S Server Side Analyzers]
eValid Home
Summary
Tests of a web server done from the client side
-- i.e. from inside a browser --
simulate user interactions by stimulating the server to
produce and deliver various pages based on
requests made by the client (the user).
eValid's in-the-browser spider examine every page viewable
and analyze the delivered contents.
The results are analyses that are extremely accurate
and 100% indicative of what users experience.
Main Advantages of Logical View
The main advantages of working
from the "logical view" of a website
using eValid's unique browser-based approach
to website analysis and quality assurance include:
- Accurate User Perspective.
The analysis is done entirely from
the point of view of a user,
based on the information that is
drawn from the web server
into the eValid browser by
requests made by eValid's automatic search spider.
- Accurate Timing.
Timing data is 100% representative of what the user sees
because the measurements are done
100% from the client perspective.
Download times includes the time it takes to
fully download and render the page.
- Accurate Sizes.
Size calculations for pages,
constituent elements, images, and other files,
are always based on
the information actually delivered by the server
to the evalid browser.
- Accurate Dynamic Content.
Only content actually generated by the server is analyzed at
the receiving end.
evalid's browser based approach is
immune to all server implementation details,
and only analyzes the material generate in response to
a browser request.
- Actual Link Dependence Structure.
Some links may not be explicit in file-based scans.
Only actual active links are used by eValid.
Parent and child relationships between pages,
and between pages and page components,
are 100% accurate.
- Handles Secure Protocols.
Special protcols, including HTTP/S,
require no special modification or support.
- Handles Browser Plugins.
The client-side approach handles browser plugins and
all other types of client-side appliances.
- Accurate Metrics.
Metric data collected for pages reflects
the information known to the eValid browser,
within the Document Object Model (DOM).
(Metric data other than basic size
and download time
is not usually collected for page components
such as *.gifs and *.jpgs.)
As a consequence,
page complexity details pertain specifically
to what is seen by the user,
and is not based on server-internal complexity.
- Handles Login Sites.
If a website requires a login,
eValid's functional testing component can
play back the login sequence and issue
the site analysis start command after successfully logging in.
- Special Page Scan Logic.
Because the entire delivered page is available
for analysis,
the completely HTML, visible text, META tags, or TITLE tag
can be scanned for
presence or absence of
strings or regular expressions.
- No Special Access Rights Required.
Because the analysis is done with
information accessible by the public,
no special access rights are required to read server-side files.
The Logical View
What happens when, in a web page,
you click on a hypertext link
to request that the server deliver you (the browser)
a new page.
The server generates the page and sends it to the browser.
In turn,
the browser may request additional pages based on what it was just sent.
Modern browsers -- eValid included -- launch multiple threads to help
get the complete page to you as fast as possible.
For example, pictures (images) or
cascading style sheets or
JavaScript files
are all requested automatically by the browser
if the page to which you just navigated references them.
(There are many ways a base page can make requests for secondary pages.)
Modern web servers generally compose the page that you see by
assembling the page from many components, fragments, parts, and pieces.
What you see are pages; you don't see the components that the
server used to create them.
(In older, so-called flat-file sites,
every page does correspond to a file on the server.)
As the picture below shows,
web page dependencies and structures are NOT
the same as files.
WebSite analyzers that operate on the server side use files which
may or may not be actual visible, browsable entities.
Note that none of the entities shown is specifically a "file" but
instead are all logical units as seen from,
and processed by,
the browser.
Client Site (Browser Based) View Of Web Pages
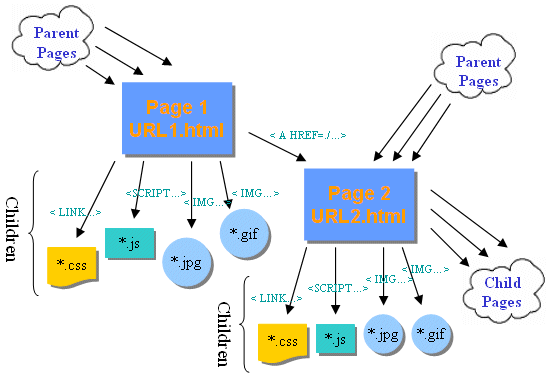
|
The diagram illustrates the logical structure of a website and
is the basis for the above discussion.
- Page Link.
Page 1 (URL1.html) has a link to
Page 2 implemented in a <A HREF=.. > tag.
Page 2 is a child of Page 1.
- Parent Page Links.
There are possibly many other links from other pages [parents]
to Page 1 or Page 2.
On websites pages can refer to themselves
(making them their own parents),
or they may refer to pages that refer to them
(circular dependence).
- Child Page Links.
There are possibly many other links to other pages [children]
to Page 1 or Page 2.
On websites pages can refer to themselves
(making them their own children),
or they may refer to pages that refer to them
(circular dependence).
- Component Links.
Both Page2 and Page2 have of connections
-- which are also called --
to constituent files via a variety of HTML
methods such as:
LINK...,
SCRIPT...,
and
IMG...
among many others.
In most cases components don't have links to other
parts of the website.
Why Is Browser Mode Operation Important?
InBrowser™ Advantages for Site Analysis
Why Is Browser State Dependence Important? [eValid vs. HTTP Recorders]